데이터 전처리할 때, 범주형 데이터와 수치형 데이터를 구분해주고 적절하게 처리해주는 과정이 필요하다.
이 때 사용하는 여러 데이터 타입 관련 함수를 알아보자.
간단한 데이터셋을 만들어준다. (오늘도 열일하는 chatGPT)
import pandas as pd
data = {'name': ['John', 'Mary', 'Sara', 'David', 'Peter'],
'age': [25, 30, 35, 40, 45],
'city': ['New York', 'San Francisco', 'Boston', 'Chicago', 'Miami'],
'salary': ['2500', '3000', '3500', '4000', '4500']}
df = pd.DataFrame(data)
df
습관처럼 사용해주는 info() 를 이용해주면, 데이터 타입을 확인할 수 있다.
df.info()
하지만 info() 는 데이터 타입부터 null값 개수 등 여러가지 정보를 포함하고 있기 때문에,
데이터 타입만을 확인하고 싶은 경우는 dtypes를 사용해주는 것이 편하다.
참고) column 하나만 확인하고 싶으면 dtype를 써줘야한다. (단복수에 예민하네)
df.dtypes
만약 데이터 타입 별로 몇 개의 변수가 있는지 확인하고 싶으면, groupby로 묶어서 타입 별 개수를 세주면 된다.
df_dtypes = df.dtypes.reset_index()
df_dtypes.columns = ['column', 'dtypes']
df_dtypes.groupby('dtypes').count().reset_index()
그 결과, int 타입이 1개, object 타입이 3개인 것을 확인하였다.
그런데 위 데이터에서, salary가 int 타입으로 보이지만 컴퓨터는 object 타입으로 생각하고 있다.
잘못된 데이터 타입으로 저장되어 있기 때문에 이렇게 되면 우리가 파생변수를 만들거나 그래프를 그리거나 할 때 아주 번거로워진다. 따라서 데이터 타입을 숫자형으로 변경해주자.
1) astype
astype()안에 dictionary 형태로 column 명과 바꿀 데이터 타입을 입력해주면 된다. (float, int, string..)
df = df.astype({'salary' : 'int'}) #언제나 기억하자. 저.장.
df.dtypes
근데 이제 astype이 만능인 것은 아니다.
새로운 데이터셋을 만들어주고 살펴보면,
data = {'name': ['John', 'Mary', 'Sara', 'David', 'Peter'],
'age': [25, 30, 35, 40, 45],
'city': ['New York', 'San Francisco', 'Boston', 'Chicago', 'Miami'],
'salary': ['2500', '3000', '3500', '4000', '-']}
df = pd.DataFrame(data)
df
똑같이 astype을 실행했을 때...........!
df = df.astype({'salary' : 'int'})
df.dtypes
에.러.발.생.
'-'를 int 타입으로 바꿔줄 수 없다고 한다.
이럴 때 사용해주는게 to_numeric()이다.
2) to_numeric
아래와 같이 errors = 'coerce'를 꼭 입력해줘야 한다.
이렇게 하면 '-' 값은 숫자형으로 바꿀 수 없기 때문에 결측치(np.nan)로 대체해주고 나머지 값들에 대해서 숫자형으로 변환해준다.
df['salary'] = pd.to_numeric(df['salary'], errors = 'coerce') # 언제나 기억하자 저.장.
df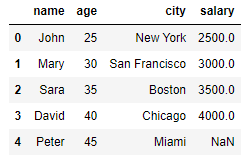
여기서 나는 int로 바꾸고 싶은데 해당 열이 float 타입으로 변환되었음을 알 수 있다.
결측치가 포함되어 있기 때문에 해당 열이 자동으로 float으로 인식되는 것으로 int 타입으로 바꾸고 싶다면 결측치를 처리해주고 astype을 쓰든, to_numeric을 쓰든 바꿔주면 된다.

참고로
errors = {'ignore', 'raise', 'coerce'} (default : 'raise')가 있는데,
디폴트가 'raise'이기 때문에 안 써주면 astype()과 똑같이 그냥 에러가 발생한다.
'ignore'을 써주면 그냥 무시하고 바꿔주지 않는다....
coerce의 뜻은 '강제한다'라는 뜻으로 바꿀 수 없는 값을 강제로 NaN으로 바꿔준다는 의미인 것 같다.
그렇다면 astype과 to_numeric의 차이가 무엇일까..
일단, 가장 큰 차이는 위에서 언급했듯이 '결측치 처리 방법'이다. astype은 무조건 error를 발생시키지만 to_numeric은 error를 발생시키지 않고 결측치로 대체해 줄 수 있다.
다음으로 astype은 열을 원하는 데이터 타입으로 바꿔줄 수 있다. 반면 to_numeric은 함수 이름에서부터 알 수 있듯이 숫자형으로 바꿔주는 함수이다.(번외편으로 to_datetime과 같은 애들이 있지만 다음시간에..)
마지막으로 astype은 여러 열을 한 번에 원하는 데이터 타입으로 처리할 수 있다. 반면 to_numeric은 인자로 1-d array나 series, scalar, list, tuple만 취급한다. 이 말은 하나의 열만 데이터 타입을 숫자형으로 변경해 줄 수 있다는 것이다.
따라서 결측치가 없다면 astype으로 한번에 원하는 데이터 타입으로 바꿔주고, 결측치가 있는 열에 대해서만 to_numeric으로 처리해주면 편할 것 같다.
'Basic > [Pytohn] Numpy, Pandas' 카테고리의 다른 글
| [pandas] 결측치 확인, 제거 (0) | 2023.03.29 |
|---|---|
| [pandas] 중복값 제거_duplicated() , drop_duplicates() (0) | 2023.03.16 |

